Multimodal Deep Learning for Visual Question Answering
Visual Question Answering (VQA) is a deep learning task where a model is given an image and a related question and must generate a correct answer based on the information in the image. The challenge lies in the model's ability to understand both the visual content and the semantics of the question, requiring it to implicitly reason about the relationships between objects in the image and the details asked in the question. This task is more complex than simple image classification, as the model must comprehend the image and answer specific questions related to its contents.
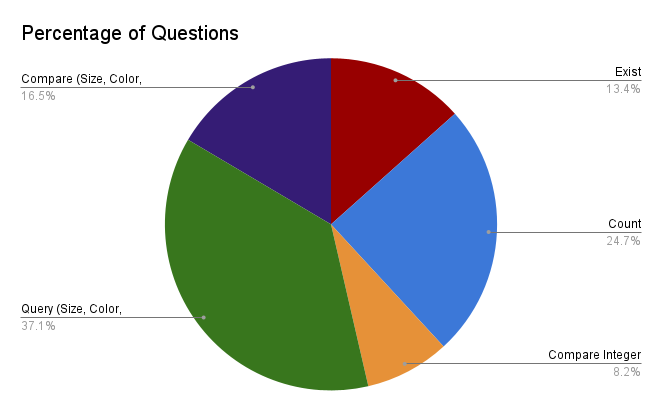
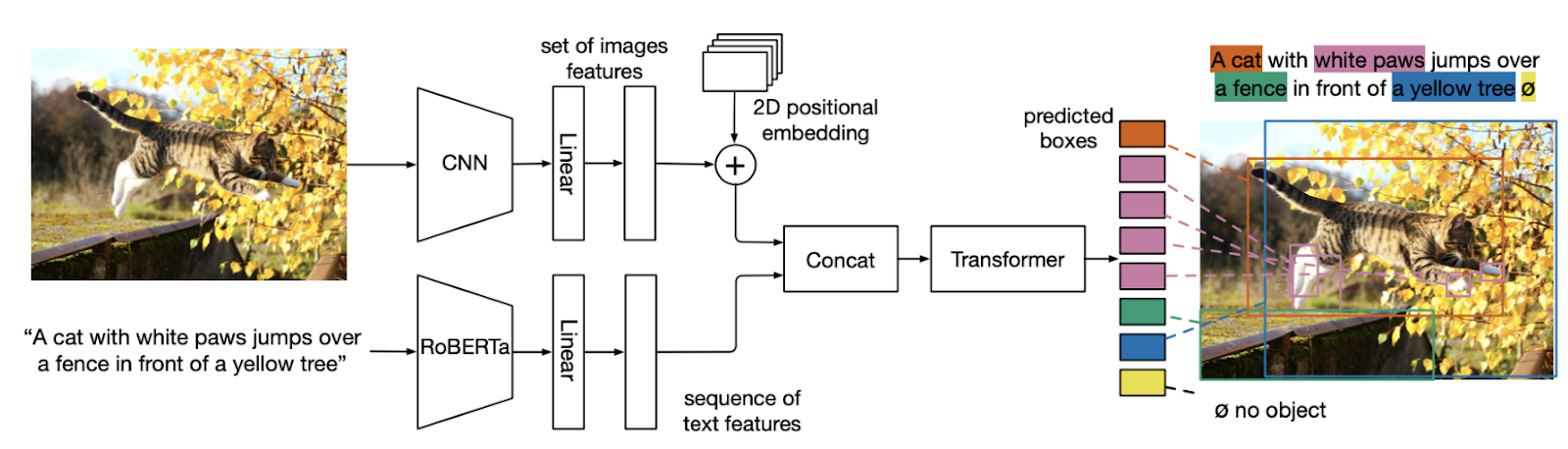
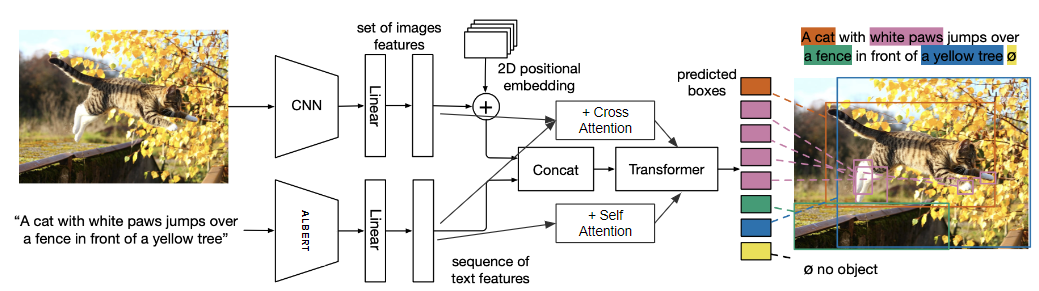
To tackle this, we built a transformer-based model, which has proven effective in handling tasks that require understanding both images and text. Transformers, particularly those utilizing attention mechanisms, are capable of processing complex relationships between visual elements and textual queries, making them well-suited for VQA. We trained our model using the **Neural Symbolic VQA** dataset, a state-of-the-art dataset designed for this task, which includes a wide range of questions and images that challenge the model’s ability to reason and understand context.
Our model achieved a **maximum accuracy of 70%** on the dataset, which is promising given the challenges of VQA tasks. However, due to time constraints, the model was not fully trained, and there is potential for further improvements with more training data and fine-tuning. While our results are encouraging, we recognize that VQA models still face difficulties with complex reasoning tasks, and future work could focus on improving multi-step reasoning and handling more intricate questions.
Despite these challenges, our work highlights the potential of transformer-based models for VQA tasks and opens the door to applications in areas such as human-computer interaction, robotics, and automated content generation. With further advancements in model architectures and training techniques, VQA systems are expected to become more accurate and effective in interpreting and answering questions about images.